![[Compaq]](../../images/compaq.gif)
![[Go to the documentation home page]](../../images/buttons/bn_site_home.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs.gif)
![[Help on this site]](../../images/buttons/bn_site_help.gif)
![[How to contact us]](../../images/buttons/bn_comments.gif)
![[OpenVMS documentation]](../../images/ovmsdoc_sec_head.gif)
| Document revision date: 19 July 1999 | |
|
|
|
|
|
|
| Previous | Contents | Index |
When overlapping the execution of instructions, the vector processor must deal with register conflict. This occurs when one instruction is intending to write a register while previously issued instructions are reading from that register. The following is an example of vector register conflict:
VVADDF V1, V2, V3 VVMULF V4, V5, V1 |
In the example, the VVADDF and VVMULF cannot both begin execution simultaneously because the elements of V1 generated by the VVMULF would overwrite the original elements of V1 required as input by the VVADDF. However, a vector processor implementation can still overlap the execution of these two instructions in a number of ways. One way would be by not starting the VVMULF until the first element of V1 has been read by the VVADDF. In this manner, as the VVADDF reads the next elements from V1 and V2, the VVMULF writes its product into the previous element of V1. This process continues until all the elements have been processed by both instructions. The VVADDF will finish execution while the VVMULF still has at least one product to store.
In the case of the Vector Mask Register (VMR), the vector processor
ensures that register conflict does not occur. This is often
accomplished by making a copy of the VMR value under which a pending
vector instruction is to execute, and using this copy when execution
begins. This allows the vector processor to begin executing an
instruction that writes VMR before it completes prior instructions that
read VMR.
1.5.3.3 Dependencies Among Vector Results
To achieve correct results and exception reporting during overlapped execution, the vector processor must maintain certain dependencies among the register elements and control register bits produced by various vector instructions. Because of the vector processor's asynchronous exception reporting nature and out-of-order completion of instructions, these dependencies differ from those ensured by the VAX scalar processor. In addition, these dependencies are at the level of vector register elements and vector control register bits; rather than at the level of vector registers and vector control registers.
Among other things, these dependencies determine the exception reporting nature of the MFVP instruction. The value of the vector control register (VCR, VLR, VMR<31:0>, VMR<63:32>) delivered by an MFVP depends upon the value of certain vector register elements and vector control register bits. Unreported exceptions that occur in the production of these elements and control register bits are reported by the vector processor prior to the completion of the MFVP from the vector control register.
The dependencies are expressed formally for the various classes of vector instructions by the tables of pseudo-code in this section. These are the only dependencies that software should rely upon the vector processor to ensure.
A vector processor implementation is allowed to ensure more than just these dependencies providing that this larger set of dependencies yields correct results and exception reporting.
Note the implications of the following sequence for Table 1-7, Table 1-8, Table 1-9, Table 1-10, Table 1-11, Table 1-12, Table 1-13, and Table 1-14:
Implicit in statements of the form: "result DEPENDS on B" is the requirement that the result depends only on the value of "B" generated by the most immediate previously issued instruction relative to the result's own generating instruction. For instance, in the following example, the V3 produced by the VVMULF has the dependence: "V3[i] DEPENDS on V7[i]". This means that the value of V3[i] produced by the VVMULF depends only on the value of V7[i] produced by the VVADDF. |
| Instructions | Dependence |
|---|---|
| VVADDx, VSADDx, VVSUBx, VSSUBx, VVMULx, VSMULx, VVDIVx, VSDIVx, VVCVTxy, VVBICL, VSBICL, VVBISL, VSBISL, VVXORL, VSXORL, VVSLLL, VSSLLL, VVSRLL, VSSRLL |
for i = 0 to VLR-1 |
| Instructions | Dependence |
|---|---|
| VLDx, VGATHx |
for i = 0 to VLR-1 |
| Instructions | Dependence |
|---|---|
| VSTx, VSCATx |
j = 0; |
| Instructions | Dependence |
|---|---|
| VVCMPx, VSCMPx |
for i = 0 to VLR-1 |
| Instructions | Dependence |
|---|---|
| VVMERGE, VSMERGE |
for i = 0 to VLR-1 |
| Instruction | Dependence |
|---|---|
| IOTA |
j = 0; |
| Instructions | Dependence |
|---|---|
| MSYNC |
DEPENDS on the following:
|
| SYNC | DEPENDS on the vector register elements and vector control register bits produced and stored by all previous vector instructions |
| MFVMRLO | DEPENDS on VMR<0..31> |
| MFVMRHI | DEPENDS on VMR<32..63> |
| MFVCR | DEPENDS on VCR |
| MFVLR | DEPENDS on VLR |
| Item | Dependence |
|---|---|
| VSYNC | Depends on nothing, but for each memory location, x forces all subsequent LOAD_COMPLETED(x) and STORE_COMPLETED(x) to DEPEND on all previous LOAD_COMPLETED(x) and STORE_COMPLETED(x). |
| MTVP | DEPENDS on nothing. |
| Value of a memory location | The value of a memory location DEPENDS on nothing and is not DEPENDED on by any vector instruction. |
| Transitive dependence |
if {a DEPENDS on b} AND {b DEPENDS on c} then a DEPENDS on c
|
There are two major classes of vector processor exceptions as follows:
Vector processor arithmetic exceptions cause the vector processor to
disable itself (see Section 1.6.3, Vector Processor Disabled). The
vector processor does not disable itself for vector processor memory
management exceptions.
1.6.1 Vector Memory Management Exception Handling
Vector processor memory management exceptions are taken through the system control block (SCB) vector for their scalar counterparts. Figure 1-12 illustrates the memory management fault stack frame that contains the memory management fault parameter.
Figure 1-12 Memory Management Fault Stack Frame (as Sent by the Vector Processor)
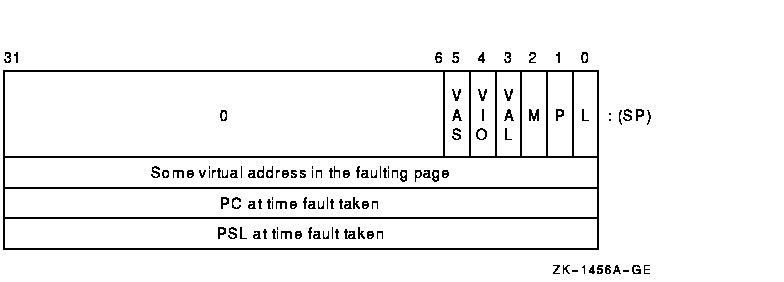
If more than one kind of memory management exception could occur on a reference to a single page, then access control violation takes precedence over both translation not valid and modify. If more than one kind of access control violation could occur, the precedence of vector access control violation, vector alignment exception, and vector I/O space reference is UNPREDICTABLE.
The architecture allows an implementation to choose one of two methods for dealing with vector processor memory management exceptions. The two methods are as follows:
With the synchronous method, no new instructions are processed by the vector or the scalar processor until the vector memory access instruction is guaranteed to complete without incurring memory management exceptions. In such an implementation, the vector memory access instruction is backed up when a memory management exception occurs and a normal VAX memory management (access control violation, translation not valid, modify) fault taken with the program counter (PC) pointing to the faulting vector memory access instruction. If the synchronous method is implemented, VSAR is omitted. After fixing the vector processor memory management exception, software may REI back to the faulting vector instruction. Alternately, software may context switch to another process. For further details, see Section 1.6.4.
With the asynchronous method, vector memory management exceptions set VPSR<PMF> and VPSR<MF>. The vector processor does not inform the scalar processor of the exception condition; the scalar processor continues processing instructions. All pending vector instructions that have started execution are allowed to complete if their source data is valid. The scalar processor is notified of an exception condition or conditions when it sends the next vector instruction to the vector processor and a normal VAX memory management fault is taken. The saved PC points to this instruction, which is not the vector memory access instruction that incurred the memory management exception. At this point, the vector processor clears VPSR<PMF>. After fixing the vector processor memory management exception, software may allow the current scalar/vector process to continue. Before vector processor instruction execution resumes using state that already exists in the vector processor, the vector processor clears VPSR<MF> and the faulting memory reference is retried. Alternately, software may context switch to another process. For further details, see Section 1.6.4.
When a vector processor memory management exception is encountered by a
VLD or VGATH instruction, the contents of the destination vector
register elements are UNPREDICTABLE. When a vector processor memory
management exception is encountered by a VSTL or VSCAT instruction, it
is UNPREDICTABLE whether the vector processor writes any result
location for which an exception did not occur. In either case, if the
fault condition can be eliminated by software and the instruction
restarted, then the vector processor will ensure that all destination
register elements or result locations are written.
1.6.2 Vector Arithmetic Exceptions
Vector operate instructions are always executed to completion, even if a vector arithmetic exception occurs. If an exception occurs, a default result is written. The default result is as follows:
The exception condition type and destination register number are always
recorded in the Vector Arithmetic Exception Register (VAER) when a
vector arithmetic exception occurs. Refer to Section 1.2.3, Internal
Processor Registers, for more information.
1.6.3 Vector Processor Disabled
As a result of error conditions or software control, the vector processor signals the scalar processor not to issue any more vector instructions. The vector processor is disabled when this signal is generated and its state is reflected in VPSR<VEN>. Because the scalar and vector processors can execute asynchronously, the scalar processor may not receive this signal immediately. As a result, the scalar processor may continue to view the vector processor as enabled and send it vector instructions. Once the scalar processor receives this signal, it will view the vector processor as disabled and will not send it any more vector instructions (including MFVP/MTVP). While the vector processor is disabled, and in the absence of hardware errors, it will complete all pending instructions in its instruction queue including those sent by the scalar processor after the vector processor became disabled.
The vector processor can either disable itself or be disabled by software. The following error conditions cause the vector processor to disable itself:
In these cases, the vector processor clears VPSR<VEN> and flags the error condition by setting the appropriate bit in VPSR. (See Table 1-1.)
Software disables the vector processor by writing a zero into VPSR<VEN> using an MTPR instruction. Once the vector processor is disabled, only software can enable it. The software does this by writing a one to VPSR<VEN> using an MTPR. Recall that after performing an MTPR to VPSR, software must then issue an MFPR from VPSR to ensure that the new state of VPSR will affect the execution of subsequently issued vector instructions. The MFPR will not complete in this case until the new state of the vector processor becomes visible to the scalar processor.
When the vector processor disables itself due to a hardware error, it is implementation dependent whether the vector processor completes any pending vector instruction. However, in this case, the vector processor ensures when it is reenabled that all incompleted instructions have been flushed from the instruction queue.
If the scalar processor attempts to issue a vector instruction after it views the vector processor as disabled, then a vector processor disabled fault occurs. The vector processor disabled fault uses SCB offset 68 (hex). The exception handling software (running on the scalar processor) can then read the vector internal processor registers (IPRs) with MFPR instructions to determine what exception conditions are recorded in the vector processor and if the vector processor is still busy processing other unfinished instructions.
Once the scalar processor views the vector processor as disabled, the
only operations that can be issued to the vector processor are MTPR and
MFPR to and from the vector IPRs.
1.6.4 Handling Disabled Faults and Vector Context Switching
The following flow outlines the required steps for handling a vector processor disabled fault.
If the new process executing on the scalar processor has a vector instruction to execute, saving and restoring the state of the vector processor---that is, vector context switching---is done as part of handling a subsequent vector processor disabled fault.
If a vector processor disabled fault occurs and the current scalar process is also the current vector process, then software must perform the following procedure:
If a vector processor disabled fault occurs and the current scalar process is not the current vector process, then software must perform the following procedure:
| Previous | Next | Contents | Index |
|
|
| privacy and legal statement | ||
| 4515CH10_002.HTML | ||