![[Compaq]](../../images/compaq.gif)
![[Go to the documentation home page]](../../images/buttons/bn_site_home.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs.gif)
![[Help on this site]](../../images/buttons/bn_site_help.gif)
![[How to contact us]](../../images/buttons/bn_comments.gif)
![[OpenVMS documentation]](../../images/ovmsdoc_sec_head.gif)
| Document revision date: 19 July 1999 | |
|
|
|
|
|
|
| Previous | Contents | Index |
There exist conditions when VSYNC is not required between conflicting vector memory accesses. A VSYNC is not required before a vector memory store instruction (VST/VSCAT) if, for each memory location to be accessed by the store, both of the following conditions are met:
In all other cases of conflicting vector memory accesses, VSYNC is necessary to ensure correct results.
Examples Where VSYNC Is Not Required
In the following examples, VSYNC is not required because both of the previous conditions have been met for each location accessed by the store instruction:
| #1 |
|---|
VLDL A, #4, V0
VSTL V0, A, #4
|
| #2 |
|---|
VLDL A, #4, V0
VSSUBL R0, V0, V1
VSTL V1, A, #4
|
| #3 |
|---|
VLDL/0 A, #4 ,V0
VSMULL/0 #3, V0, V0
VLDL/1 A, #4 ,V1
VVMULL/1 V1, V1, V1
VVMERGE/1 V1, V0, V2
VSTL V2, A, #4
|
| #4 |
|---|
VLDL A, #4 ,V0
VSGTRF #0, V0
VLDL/1 B, #4, V1
VLDL/0 C, #4, V2
VVMERGE/0 V2, V1, V3
VSTL V3, A, #4
|
Examples Where VSYNC Is Required
In the following examples, VSYNC is required before the vector memory store instruction:
| #1 |
|---|
VLDL/1 A,#4,V0
VSLSSL #0,V1
VSYNC
VSTL/1 V1,A,#4
|
If the VSYNC is not included, V0 could contain incorrect data at the end of the sequence since the vector processor is allowed to begin the VSTL before the VLDL is finished. This occurs because there is no dependence between the VMR value used by the VLDL and the VSTL.
| #2 |
|---|
VLDL A, #4, V0
VVMERGE/0 V0, V1, V1
VSYNC
VSTL V1, A, #4
|
Unless the programmer can ensure that the VMR mask being used by the VVMERGE will force the access of each location by the VSTL to depend on the access to that location by the VLDL, a VSYNC is required. Note that in general, when masked operations provide a conditional path of dependence between conflicting memory accesses, a VSYNC is usually necessary to ensure correct results.
| #3 |
|---|
VSTL V1, A, #4
MTVLR #32
VSYNC
VLDL A+128, #4, V2
|
In this example, the VSTL writes locations A to A+255 and the VLDL reads locations A+128 to A+255. Without the VSYNC, the vector processor is allowed to start reading locations A+128 to A+255 for the VLDL before the vector processor completes (or even starts) writing locations A+128 to A+255 for the VSTL. Consequently, V2[0:31] will not contain V1[32:63], which is the intended result. Note that the rules on when VSYNC is not required (found in Section 1.7.5.1) only apply to waiving the use of VSYNC prior to VST/VSCAT instructions.
| #4 |
|---|
VGATHL A, V2, V0 ; let at least two elements
; of V2 be equal
VVMULL V9, V0, V1
VSYNC
VSCATL V1, A, V2
|
The VSYNC is needed in this example because the VSCATL may store elements of V1 into a common location before the VGATHL has finished loading that location into all the appropriate elements of V0. As a result, elements of V0 fetched from the same location may be unequal. Suppose in the example that V2[0] = V2[63] = 0 and that the original value of location A before the sequence starts is X. Then it is possible without the VSYNC that V0[63] = X*V9[0] and that (A)= V1[63] = V9[63]*V9[0]*X after the sequence completes.
| #5 |
|---|
VLDL A, #0, V0
VVMULL V9, V0, V1
VSYNC
VSTL V1, A, #0
|
The VSYNC is needed in this example because the VSTL may store elements of V1 into A before the VLDL has finished loading all elements of V0 from A. As a result, the elements of V0 may be unequal and so produce incorrect results.
The vector processor may include its own translation buffer and maintain its own copies of SBR, SLR, SPTEP, P0BR, P0LR, P1BR, and P1LR as a group, or may use the scalar processor's memory management unit. Hardware implementations must ensure that MTPR to these registers update the copy retained by the vector processor. Changes to P0BR, P0LR, P1BR, and P1LR due to a LDPCTX do not update the copies in the vector processor. Before software enables the vector processor again, explicit MTPRs to P0BR, P0LR, P1BR, and P1LR are required to guarantee correct operation.
An MTPR to TBIS must also invalidate the corresponding TB entry in the vector processor, and an MTPR to TBIA must also invalidate the entire TB in the vector processor. However, the vector TB is not invalidated by a LDPCTX instruction. Software can use an MTPR to the Vector TB Invalidate All (VTBIA) register to invalidate only the vector TB. An MTPR to VTBIA results in no operation on a processor that uses a common TB for the scalar and vector processors.
Updates to memory management registers and invalidates of translation buffer entries in the vector processor take place even when the vector processor is disabled (VPSR<VEN> is clear). However, the vector processor may load translation buffer entries only when the vector processor is executing a vector memory access instruction.
The vector processor implements the modify-fault option if its scalar processor implements the virtual-machine option.
Vector memory access instructions must not be used to read or write page tables. If a vector instruction is used to read or write page tables, the results are UNPREDICTABLE.
Vector instructions are not allowed to reference I/O space. If a vector instruction references I/O space, the results are UNPREDICTABLE.
Issuing vector instructions with memory management disabled causes the
operation of the vector processor to be UNDEFINED. Disabling memory
management when the vector processor is busy (VPSR<BSY> is set)
also causes the operation of the vector processor to be UNDEFINED.
1.9 Hardware Errors
A vector processor implementation may experience error conditions (such as chip malfunctions, parity errors, or bus errors) that prevent it from executing and completing instructions and from which it cannot recover through its own means. Such errors are termed hardware errors and may occur at anytime, even when the vector processor is already disabled. Vector processor hardware errors do not normally halt the scalar processor.
At some point after the error condition occurs, the vector processor reports the error to the scalar processor. The reporting may be accomplished through a machine check; or by disabling the vector processor, setting VPSR<IMP>, and generating a vector processor disabled fault when the next vector instruction is issued. After the error is reported, the appropriate software handler will be invoked to diagnose the vector processor and to determine the severity of the hardware error and whether the vector processor can be restarted.
During execution, software may wish to force the reporting of hardware errors encountered by previous vector instructions before issuing further ones. This can be accomplished by reading the VMAC internal processor register (IPR) and by waiting for VPSR<BSY> to become clear.
An MFPR from VMAC ensures that all pending vector memory instructions have finished or are suspended by an asynchronous memory management exception, and that all vector-processor hardware errors encountered by these instructions are reported by the time the MFPR completes. Errors are handled as follows:
Waiting for VPSR<BSY> to become clear before issuing further instructions ensures that all previous non-memory-access instructions have been finished or are suspended by an asynchronous memory management exception, and that all vector-processor hardware errors encountered by these instructions are reported by the time VPSR<BSY> becomes clear. Errors are handled as follows:
VMAC does not ensure that hardware errors encountered by pending non-memory-access instructions will be reported. Waiting for VPSR<BSY> to become clear does not ensure that vector-processor hardware errors encountered by vector memory instructions are reported.
Software can force the reporting of hardware errors encountered during
the execution of previous vector instructions (both memory and
non-memory) by waiting for VPSR<BSY> to become clear and then by
issuing an MFPR from VMAC. This technique can be used during scalar
context switching to cause hardware errors resulting from the execution
of vector instructions for the current process to be reported before
that process is context-switched.
1.10 Vector Memory Access Instructions
There are alignment, stride, address specifier context, and access mode
considerations for the vector memory access instructions.
1.10.1 Alignment Considerations
Vector memory access instructions require their vector operands to be naturally aligned in memory. Longwords must be aligned on longword boundaries. Quadwords must be aligned on quadword boundaries. If any vector element is not naturally aligned in memory, an access control violation occurs. For further details, see Section 1.6.1, Vector Memory Management Exception Handling.
The scalar operands need not be naturally aligned in memory.
1.10.2 Stride Considerations
A vector's stride is defined as the number of memory locations (bytes)
between the starting address of consecutive vector elements. A
contiguous vector that has longword elements has a stride of four; a
contiguous vector that has quadword elements has a stride of eight.
1.10.3 Context of Address Specifiers
The base address specifier used by the vector memory access
instructions is of byte context, regardless of the data type. Arrays
are addressed as byte strings. Index values in array specifiers are
multiplied by one, and the amount of autoincrement or autodecrement,
when either of these modes is used, is one.
1.10.4 Access Mode
A vector memory access instruction is executed using the access mode in
effect when the instruction is issued by the scalar processor.
1.10.5 Memory Instructions
This section describes VAX vector architecture memory instructions.
Load Memory Data into Vector Register
ArchitectureVLDL [/M[0|1]] base, stride, Vc
VLDQ [/M[0|1]] base, stride, Vc
Format
opcode cntrl.rw, base.ab, stride.rl
Opcodes
| 34FD | VLDL | Load Longword Vector from Memory to Vector Register |
| 36FD | VLDQ | Load Quadword Vector from Memory to Vector Register |
Vector Control Word
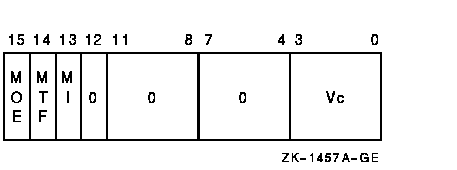
Exceptions
The source operand vector is fetched from memory and is written to vector destination register Vc. The length of the vector is specified by VLR. The virtual address of the source vector is computed using the base address and the stride. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+{i*stride}}. The stride can be positive, negative, or zero.In VLDL, bits <31:0> of each destination vector element receive the memory data and bits <63:32> are UNPREDICTABLE.
If any vector element operated upon is not naturally aligned in memory, a vector alignment exception occurs.
The results of VLD are unaffected by the setting of cntrl<MI>. For more details about the use of cntrl<MI>, see Section 1.3.3, Modify Intent bit.
If the addressing mode of the BASE operand is immediate, the results of the instruction are UNPREDICTABLE.
An implementation may load the elements of the vector in any order, and more than once. When a vector processor memory management exception occurs, the contents of the destination vector elements are UNPREDICTABLE.
Gather Memory Data into Vector Register
ArchitectureVGATHL [/M[0|1]] base, Vb, Vc
VGATHQ [/M[0|1]] base, Vb, Vc
Format
opcode cntrl.rw, base.ab
Opcodes
| 35FD | VGATHL | Gather Longword Vector from Memory to Vector Register |
| 37FD | VGATHQ | Gather Quadword Vector from Memory to Vector Register |
vector_control_word
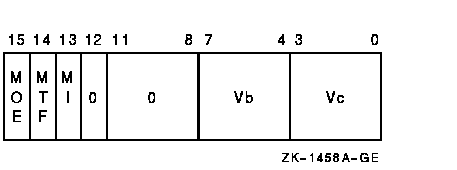
Exceptions
The source operand vector is fetched from memory and is written to vector destination register Vc. The length of the vector is specified by VLR. The virtual address of the vector is computed using the base address and the 32-bit offsets in vector register Vb. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+Vb[i]}. The 32-bit offset can be positive, negative, or zero.In VGATHL, bits <31:0> of each destination vector element receive the memory data and bits <63:32> are UNPREDICTABLE.
If any vector element operated upon is not naturally aligned in memory, a vector alignment exception occurs.
The results of VGATH are unaffected by the setting of cntrl<MI>. For more details about the use of cntrl<MI>, see Section 1.3.3, Modify Intent bit.
If the addressing mode of the BASE operand is immediate, the results of the instruction are UNPREDICTABLE.
An implementation may load the elements of the vector in any order, and more than once. When a vector processor memory management exception occurs, the contents of the destination vector elements are UNPREDICTABLE.
If the same vector register is used as both source and destination, the result of the VGATH is UNPREDICTABLE.
Store Vector Register Data into Memory
ArchitectureVSTL [/0|1] Vc, base, stride
VSTQ [/0|1] Vc, base, stride
Format
opcode cntrl.rw, base.ab, stride.rl
Opcodes
| 9CFD | VSTL | Store Longword Vector from Vector Register to Memory |
| 9EFD | VSTQ | Store Quadword Vector from Vector Register to Memory |
vector_control_word
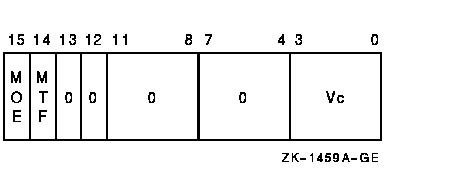
Exceptions
The source operand in vector register Vc is written to memory. The length of the vector is specified by the Vector Length Register (VLR). The virtual address of the destination vector is computed using the base address and the stride. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+{i*stride}}. The stride can be positive, negative, or zero.If any vector element operated upon is not naturally aligned in memory, a vector alignment exception occurs.
For a nonzero stride value, an implementation may store the vector elements in parallel; therefore the order in which these elements are stored is UNPREDICTABLE. Furthermore, if the nonzero stride causes result locations in memory to overlap, then the values stored in the overlapping result locations are also UNPREDICTABLE.
For a stride value of zero, the highest numbered register element destined for the single memory location becomes the final value of that location.
When a vector processor memory management exception occurs, it is UNPREDICTABLE whether the vector processor writes any result location for which an exception did not occur. If the fault condition can be eliminated by software and the instruction restarted, then the vector processor will ensure that all destination locations are written.
If the destination vector overlaps the vector instruction control word, base, or stride operand, the result of the instruction is UNPREDICTABLE.
If the addressing mode of the BASE operand is immediate, the results of the instruction are UNPREDICTABLE.
Scatter Vector Register Data into Memory
ArchitectureVSCATL [/0|1] Vc, base, Vb
VSCATQ [/0|1] Vc, base, Vb
Format
opcode cntrl.rw, base.ab
Opcodes
| 9DFD | VSCATL | Scatter Longword Vector from Vector Register to Memory |
| 9FFD | VSCATQ | Scatter Quadword Vector from Vector Register to Memory |
vector_control_word
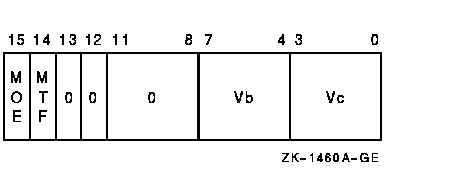
Exceptions
The source vector operand Vc is written to memory. The length of the vector is specified by the Vector Length Register (VLR) register. The virtual address of the destination vector is computed using the base address operand and the 32-bit offsets in vector register Vb. The address of element i (0 LEQU i LEQU (VLR-1)) is computed as {base+Vb[i]}. The 32-bit offset can be positive, negative, or zero.If any vector element operated upon is not naturally aligned in memory, a vector alignment exception occurs.
An implementation may store the vector elements in parallel; therefore, the order in which elements are stored to different memory locations is UNPREDICTABLE. In the case where multiple elements are destined for the same memory location, the highest numbered element among them becomes the final value of that location.
When a vector processor memory management exception occurs, it is UNPREDICTABLE whether the vector processor writes any result location for which an exception did not occur. If the fault condition can be eliminated by software and the instruction restarted, then the vector processor will ensure that all destination locations are written.
If the destination vector overlaps the vector instruction control word or base operand, the result of the instruction is UNPREDICTABLE.
If the addressing mode of the BASE operand is immediate, the results of the instruction are UNPREDICTABLE.
| Previous | Next | Contents | Index |
|
|
| privacy and legal statement | ||
| 4515CH10_004.HTML | ||