![[Compaq]](../../images/compaq.gif)
![[Go to the documentation home page]](../../images/buttons/bn_site_home.gif)
![[How to order documentation]](../../images/buttons/bn_order_docs.gif)
![[Help on this site]](../../images/buttons/bn_site_help.gif)
![[How to contact us]](../../images/buttons/bn_comments.gif)
![[OpenVMS documentation]](../../images/ovmsdoc_sec_head.gif)
| Document revision date: 19 July 1999 | |
|
|
|
|
|
|
| Previous | Contents | Index |
Vector Floating Divide
Architecturevector/vector:
[/U[0|1]] Va, Vb, Vc
- VVDIVF
- VVDIVD
- VVDIVG
scalar/vector:
[/U[0|1]] scalar, Vb, Vc
- VSDIVF
- VSDIVD
- VSDIVG
Format
vector/vector:
opcode cntrl.rw
scalar/vector (F_floating):
opcode cntrl.rw, divd.rl
scalar/vector (D_ and G_floating):
opcode cntrl.rw, divd.rq
Opcodes
| ACFD | VVDIVF | Vector Vector Divide F_floating |
| ADFD | VSDIVF | Vector Scalar Divide F_floating |
| AEFD | VVDIVD | Vector Vector Divide D_floating |
| AFFD | VSDIVD | Vector Scalar Divide D_floating |
| AAFD | VVDIVG | Vector Vector Divide G_floating |
| ABFD | VSDIVG | Vector Scalar Divide G_floating |
vector_control_word
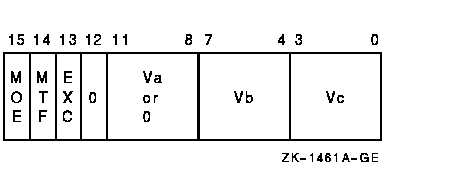
Exceptions
The scalar dividend or vector register Va is divided, elementwise, by the divisor in vector register Vb and the quotient is written to vector register Vc. The length of the vector is specified by the Vector Length Register (VLR).In VxDIVF, only bits <31:0> of each vector element participate in the operation; bits <63:32> of the destination vector elements are UNPREDICTABLE.
If a floating underflow occurs when cntrl<EXC> is set or if a floating overflow, divide by zero, or reserved operand occurs, an encoded reserved operand is stored as the result and the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER). The vector operation is then allowed to complete. If cntrl<EXC> is clear, zero is written to the destination element when an exponent underflow occurs and no other action is taken.
Vector Floating Multiply
Architecturevector * vector:
[/U[0|1]] Va, Vb, Vc
- VVMULF
- VVMULD
- VVMULG
scalar * vector:
[/U[0|1]] scalar, Vb, Vc
- VSMULF
- VSMULD
- VSMULG
Format
vector * vector:
opcode cntrl.rw
scalar * vector (F_floating):
opcode cntrl.rw, mulr.rl
scalar * vector (D_ and G_floating):
opcode cntrl.rw, mulr.rq
Opcodes
| A4FD | VVMULF | Vector Vector Multiply F_floating |
| A5FD | VSMULF | Vector Scalar Multiply F_floating |
| A6FD | VVMULD | Vector Vector Multiply F_floating |
| A7FD | VSMULD | Vector Scalar Multiply D_floating |
| A2FD | VVMULG | Vector Vector Multiply G_floating |
| A3FD | VSMULG | Vector Scalar Multiply G_floating |
vector_control_word
Exceptions
The multiplicand in vector register Vb is multiplied, elementwise, by the scalar multiplier or vector operand Va and the product is written to vector register Vc. The length of the vector is specified by the Vector Length Register (VLR).In VxMULF, only bits <31:0> of each vector element participate in the operation. Bits <63:32> of the destination vector elements are UNPREDICTABLE.
If a floating underflow occurs when cntrl<EXC> is set or if a floating overflow or reserved operand occurs, an encoded reserved operand is stored as the result and the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER). The vector operation is then allowed to complete. If cntrl<EXC> is clear, zero is written to the destination element when an exponent underflow occurs and no other action is taken.
Vector Floating Subtract
Architecturevector--vector:
[/U[0|1]] Va, Vb, Vc
- VVSUBF
- VVSUBD
- VVSUBG
scalar--vector:
[/U[0|1]] scalar, Vb, Vc
- VSSUBF
- VSSUBD
- VSSUBG
Format
vector--vector:
opcode cntrl.rw
scalar--vector (F_floating):
opcode cntrl.rw, min.rl
scalar--vector (D_ and G_floating):
opcode cntrl.rw, min.rq
Opcodes
| 8CFD | VVSUBF | Vector Vector Subtract F_floating |
| 8DFD | VSSUBF | Vector Scalar Subtract F_floating |
| 8EFD | VVSUBD | Vector Vector Subtract D_floating |
| 8FFD | VSSUBD | Vector Scalar Subtract D_floating |
| 8AFD | VVSUBG | Vector Vector Subtract G_floating |
| 8BFD | VSSUBG | Vector Scalar Subtract G_floating |
vector_control_word
Exceptions
Vector register Vb is subtracted, elementwise, from the scalar minuend or vector register Va and the difference is written to vector register Vc. The length of the vector is specified by the Vector Length Register (VLR).In VxSUBF, only bits <31:0> of each vector element participate in the operation; bits <63:32> of the destination vector elements are UNPREDICTABLE.
If a floating underflow occurs when cntrl<EXC> is set or if a floating overflow or reserved operand occurs, an encoded reserved operand is stored as the result and the exception condition type and destination register number are recorded in the Vector Arithmetic Exception Register (VAER). The vector operation is then allowed to complete. If cntrl<EXC> is clear, zero is written to the destination element when an exponent underflow occurs and no other action is taken.
This section describes VAX vector architecture edit instructions.
Vector Merge
Architecturevector vector merge:
VVMERGE [/0|1] Va, Vb, Vc
vector scalar merge:
[/0|1] src, Vb, Vc
- VSMERGE
- VSMERGEF
- VSMERGED
- VSMERGEG
Format
vector-vector: opcode cntrl.rw
vector-scalar: opcode cntrl.rw,src.rq
Opcodes
| EEFD | VVMERGE | Vector Vector Merge |
| EFFD | VSMERGE | Vector Scalar Merge |
vector_control_word
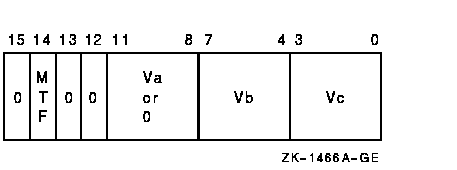
Exceptions
The scalar src or vector operand Va is merged, elementwise, with vector register Vb and the resulting vector is written to vector register Vc. The length of the vector operation is specified by the Vector Length Register (VLR).For each vector element, i, if the corresponding Vector Mask Register bit (VMR<i>) matches cntrl<MTF>, src or Va[i] is written to the destination vector element Vc[i]. If VMR<i> does not match cntrl<MTF>, Vb[i] is written to the destination vector element.
Generate Compressed Iota Vector
ArchitectureIOTA [/0|1] stride, Vc
Format
opcode cntrl.rw, stride.rl
Opcodes
| EDFD | IOTA | Generate Compressed Iota Vector |
vector_control_word
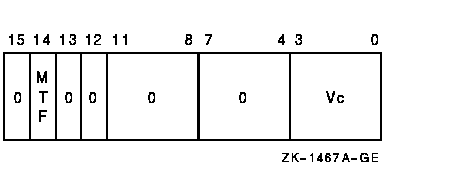
Exceptions
IOTA constructs a vector of offsets for use by the vector gather/scatter instructions VGATH and VSCAT.IOTA first generates an iota vector of length VLR using the stride operand. An iota vector is a vector whose first element is zero and whose subsequent elements are spaced by the stride increment. The stride can be positive, negative, or zero. For example:
0*stride, 1*stride, 2*stride, 3*stride, ..., {VLR-1}*strideThe iota vector is then compressed using the contents of the Vector Mask Register (VMR). Elements of the iota vector for which the corresponding Vector Mask Register bit matches cntrl<MTF> are written in contiguous elements of the destination vector register Vc. Only bits <31:0> of each iota and destination vector element participate in the operation. Bits <63:32> of the destination vector elements are UNPREDICTABLE.
The number of elements written to Vc is returned in the Vector Count Register (VCR). The values of elements in the destination vector register between the new value of VCR and the vector length are UNPREDICTABLE.
Note
If a large value is specified for the stride.rl operand, there is a chance for integer overflow during calculation of the "tmp <- tmp + stride" step. In this case, the overflow is ignored. For example:
tmp <- tmp + stride Value of tmp before above step: FFFFFF00 Value of Stride: FFFFFF00 Value of tmp + stride: 1 FFFFFE00 Since the overflow is ignored, the new value of tmp is FFFFFE00.
This section describes VAX vector architecture miscellaneous instructions.
Move from Vector Processor
Architecture
dst
- MFVCR
- MFVLR
- MFVMRLO
- MFVMRHI
- SYNCH
- MSYNCH
Format
opcode regnum.rw, dst.wl
Opcodes
| 31FD | MFVP | Move from Vector Processor |
vector_control_word
None.
Exceptions
MFVP instructions that specify reserved values of the regnum operand produce UNPREDICTABLE results.
This instruction can be used to read the Vector Count, Length, and Mask Registers, and to synchronize a scalar processor with its associated vector processor.When the scalar processor issues an MFVP instruction to the vector processor, the scalar processor waits for the MFVP result to be written before processing other instructions.
MFVP from VCR or VLR does not read that register until all previous write operations to the register are completed. MFVP from VMR<31:0> or VMR<63:32> does not read that longword of VMR until all previous write operations to the same longword of VMR are completed; however, this is not true for previous write operations to the other longword.
SYNC allows software to ensure that the unreported exceptions of all previously issued vector instructions (including vector memory instructions in asynchronous memory management mode) are detected and reported to the scalar processor before the scalar processor proceeds with further instructions. For more details about SYNC and its exception reporting nature refer to Section 1.7.1, Scalar/Vector Instruction Synchronization.
MSYNC allows software to ensure that all previously issued memory instructions of the scalar/vector processor pair are complete before the scalar processor proceeds with further instructions. For more details about MSYNC and its exception reporting nature, refer to Section 1.7.2, Memory Instruction Synchronization.
The value of the vector control register (VCR, VLR, VMR<31:0>, VMR<63:32>) delivered by an MFVP depends upon the value of certain vector register elements and vector control register bits. Unreported exceptions that occur in the production of these elements and control register bits are reported by the vector processor prior to the completion of the MFVP from the vector control register.
In addition, there are vector register elements and vector control register bits that the value of a vector control register delivered by an MFVP does not depend upon. It is UNPREDICTABLE whether unreported exceptions that occur in the production of these elements and control register bits are reported by the vector processor prior to the completion of the MFVP from the vector control register. Software must not rely upon the reporting of these exceptions prior to the completion of the MFVP for the correctness of program results.
Section 1.5.3.3, Dependencies Among Vector Results, gives the necessary rules to determine what vector control register elements and vector control register bits the value of a vector control register delivered by an MFVP depends upon. Examples of MFVP exception reporting using these rules are found in Section 1.6.5.
When a vector arithmetic exception or memory management exception (in asynchronous memory management mode) is reported prior to the completion of an MFVP, the following occur:
- The operation of the MFVP does not complete.
- No longword result is written to the scalar destination of the MFVP by the scalar processor.
- The MFVP itself (rather than the next vector instruction) takes either a vector processor disabled fault or a memory management fault.
After the appropriate fault has been serviced, the MFVP may be returned to through an REI. If both exception conditions are encountered by an MFVP, then the MFVP itself takes a vector processor disabled fault. In this case, after the vector processor disabled fault has been serviced, returning to the MFVP instruction will cause the asynchronous memory management exception to be reported.
Move to Vector Processor
Architecture
src
- MTVCR
- MTVLR
- MTVMRLO
- MTVMRHI
Format
opcode regnum.rw, src.rl
Opcodes
| A9FD | MTVP | Move to Vector Processor |
vector_control_word
None.
Exceptions
Move to Vector Processor instructions that specify reserved values of the regnum operand produce UNPREDICTABLE results.
This instruction can be used to write the Vector Count, Length, and Mask Registers.The new value of VCR, VLR, or VMR does not affect any prior instructions. The new value remains in effect for all subsequent vector instructions executed until a new value is loaded.
Synchronize Vector Memory Access
ArchitectureVSYNCH
Format
opcode regnum.rw
Opcodes
| A8FD | VSYNC | Synchronize Vector Memory Access |
vector_control_word
None.
Exceptions
Synchronize Vector Memory Access instructions that specify reserved values of the regnum operand produce UNPREDICTABLE results.
The VSYNC instruction can be used to synchronize memory access within the vector processor. The instruction allows software to order the conflicting memory accesses of vector-memory instructions issued after VSYNC with those of vector-memory instructions issued before VSYNC. Specifically, VSYNC forces the access of a memory location by any subsequent vector-memory instruction to wait for (depend upon) the completion of all prior conflicting accesses of that location by previous vector-memory instructions. See Section 1.7.1 for more details.See Section 1.7.5, Required Use of Memory Synchronization Instructions, for the conditions when VSYNC is not required before a vector store instruction.
| Index | Contents |
|
|
| privacy and legal statement | ||
| 4515CH10_006.HTML | ||